

Strategic AI Skills Every Librarian Must Develop
In 2026, librarians who understand how AI works will be better equipped to support students and researchers, organise collections, and help patrons find reliable information faster. Developing a few key AI skills can make everyday tasks easier and open up new ways to serve your community. Why AI Skills Matter for Librarians AI tools that recommend books, manage citations, or answer basic questions are becoming more common. Learning how these tools work helps librarians: Offer smarter, faster search results. Improve cataloguing accuracy. Provide better guidance to researchers and students. Remember, AI isn’t replacing professional judgment; it’s supporting it. Core AI Literacy Foundations Before diving into specific tools, it helps to understand some basic ideas behind AI. Machine Learning Basics:Machine learning means teaching a computer to recognise patterns in data. In a library setting, this could mean analysing borrowing habits to suggest new titles or resources. Natural Language Processing (NLP):NLP is what allows a chatbot or search tool to understand and respond to human language. It’s how virtual assistants can answer questions like “What are some journals about public health policy?” Quick Terms to Know: Algorithm: A set of steps an AI follows to make a decision. Training Data: The information used to “teach” an AI system. Neural Network: A type of computer model inspired by how the brain processes information. Bias: When data or systems produce unfair or unbalanced results. Metadata Enrichment With AI Cataloguing is one of the areas where AI makes a noticeable difference. Automated Tagging: AI tools can read through titles and abstracts to suggest keywords or subject headings. Knowledge Graphs: These connect related materials, for example, linking a book on climate change with recent journal articles on the same topic. Bias Checking: Some systems can flag outdated or biased terminology in subject classifications. Generative Prompt Skills Knowing how to “talk” to AI tools is a skill in itself. The clearer your request, the better the result. Try experimenting with prompts like these: Research Prompt: “List three recent studies on community reading programs and summarise their findings.” Teaching Prompt: “Write a short activity plan for a workshop on evaluating online information sources.” Summary Prompt: “Give me a brief overview of this article’s key arguments and methods.” Adjusting tone or adding detail can change the outcome. It’s about learning how to guide the tool rather than letting it guess. Ethical Data Practices AI tools can be useful, but they also raise questions about privacy and fairness. Librarians have always cared deeply about protecting patron information, and that remains true with AI. Keep personal data anonymous wherever possible. Review AI outputs for signs of bias or misinformation. Encourage clear policies around how data is stored and used. Ethical AI is part of a librarian’s duty to maintain trust and fairness. Automating Everyday Tasks AI can take over some of the small, routine jobs that fill up a librarian’s day. Circulation: Systems can send overdue reminders automatically or manage renewals. Chatbots: Basic questions like “What are the library hours?” can be handled instantly. Collection Management: AI can spot patterns in borrowing data to suggest which books to keep, reorder, or retire. Building Your Learning Path Getting comfortable with AI doesn’t have to mean earning a new degree. Start small: Take short online courses or micro-certifications in AI literacy. Join librarian groups or online forums where people share practical tips. Block out one hour a week to try out a new tool or attend a webinar. A little consistent learning goes a long way. Making AI Affordable Many smaller libraries worry about cost, but not every tool is expensive. Free Tools: Some open-access AI platforms, like Zendy, offer affordable access to research databases and AI-powered features. Shared Purchases: Partnering with other libraries to share licenses can cut costs. Cloud Services: Pay-as-you-go plans mean you only pay for what you actually use. There’s usually a way to experiment with AI without stretching the budget. Showing Impact Once AI tools are in use, it’s important to show their value. Track things like: Time saved on cataloguing or circulation tasks. Patron feedback on new services. How often are AI tools used compared to manual systems? Numbers matter, but so do stories. Sharing examples, like a student who found research faster thanks to a new search feature, can make your case even stronger. And remember, the future of librarianship is about using AI tools in libraries thoughtfully to keep libraries relevant, reliable, and welcoming spaces for everyone. .wp-block-image img { max-width: 75% !important; margin-left: auto !important; margin-right: auto !important; }
Key Considerations for Training Library Teams on New Research Technologies
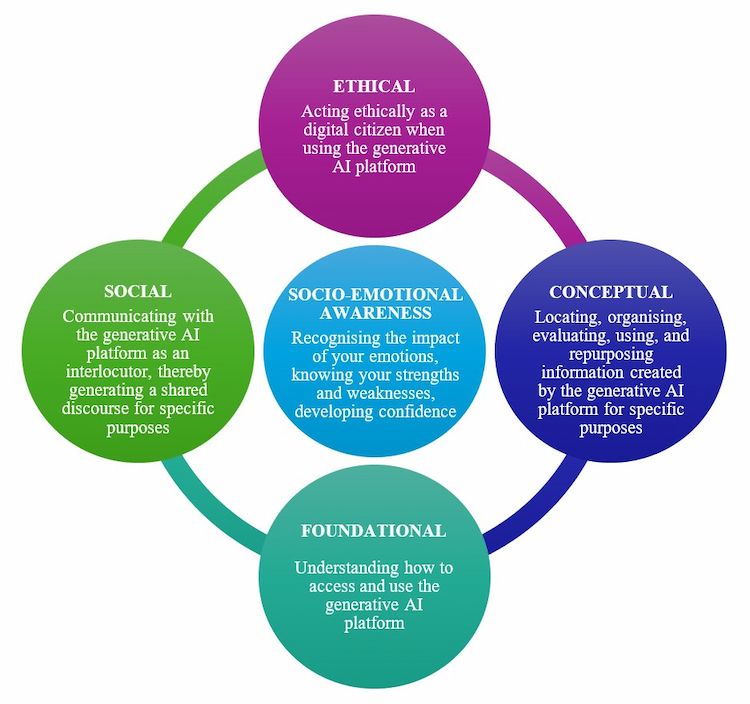
The integration of Generative AI into academic life appears to be a significant moment for university libraries. As trusted guides in the information ecosystem, librarians are positioned to help researchers explore this new terrain, but this transition requires developing a fresh set of skills. Training your library team on AI-powered research tools could move beyond technical instruction to focus on critical thinking, ethical understanding, and human judgment. Here is a proposed framework for a training program, organised by the new competencies your team might need to explore. Foundational: Understanding Access and Use This initial module establishes a baseline understanding of the technology itself. Accessing the Platform: Teach the technical steps for using the institution's approved AI tools, including authentication, subscription models, and any specific interfaces (e.g., vendor-integrated AI features in academic databases, institutional LLMs, etc.). Core Mechanics: Explain what a Generative AI platform (like a Large Language Model) is and, crucially, what it is not. Cover foundational concepts like: Training Data: Familiarise staff with how to access the institution’s chosen AI tools, noting any specific authentication requirements or limitations tied to vendor-integrated AI features in academic databases. Prompting Basics: Introduce basic prompt engineering, the art of crafting effective, clear queries to get useful outputs. Hallucinations: Directly address the concept of "hallucinations," or factually incorrect/fabricated outputs and citations, and emphasise the need for human verification. Conceptual: Critical Evaluation and Information Management This module focuses on the librarian's core competency: evaluating information in a new context. Locating and Organising: Train staff on how to use AI tools for practical, time-saving tasks, such as: Generating keywords for better traditional database searches. Summarising long articles to quickly grasp the core argument. Identifying common themes across a set of resources. Evaluating Information: This is perhaps the most critical skill. Teach a new layer of critical information literacy: Source Verification: Always cross-check AI-generated citations, summaries, and facts against reliable, academic sources (library databases, peer-reviewed journals). Bias Identification: Examine AI outputs for subtle biases, especially those related to algorithmic bias in the training data, and discuss how to mitigate this when consulting with researchers. Using and Repurposing: Demonstrate how AI-generated material should be treated—as a raw output that must be heavily edited, critiqued, and cited, not as a final product. Social: Communicating with AI as an Interlocutor The quality of AI output is often dependent on the user’s conversational ability. This module suggests treating the AI platform as a possible partner in a dialogue. Advanced Prompt Engineering: Move beyond basic queries to teach techniques for generating nuanced, high-quality results: Assigning the AI a role (such as a 'sceptical editor' or 'historical analyst') to potentially shape a more nuanced response. Practising iterative conversation, where librarians refine an output by providing feedback and further instructions, treating the interaction as an ongoing intellectual exchange. Shared Understanding: Practise using the platform to help users frame their research questions more effectively. Librarians can guide researchers in using the AI to clarify a vague topic or map out a conceptual framework, turning the tool into a catalyst for deeper thought rather than a final answer generator. Socio-Emotional Awareness: Recognising Impact and Building Confidence This module addresses the human factor, building resilience and confidence Recognising the Impact of Emotions: Acknowledge the possibility of emotional responses, such as uncertainty about shifting professional roles or discomfort with rapid technological change, and facilitate a safe space for dialogue. Knowing Strengths and Weaknesses: Reinforce the unique, human-centric value of the librarian: critical thinking, contextualising information, ethical judgment, and deep disciplinary knowledge, skills that AI cannot replicate. The AI could be seen as a means to automate lower-level tasks, allowing librarians to focus on high-value consultation. Developing Confidence: Implement hands-on, low-stakes practice sessions using real-world research scenarios. Confidence grows from successful interaction, not just theoretical knowledge. Encourage experimentation and a "fail-forward" mentality. Ethical: Acting Ethically as a Digital Citizen Ethical use is the cornerstone of responsible AI adoption in academia. Librarians must be the primary educators on responsible usage. Transparency and Disclosure: Discuss the importance of transparency when utilizing AI. Review institutional and journal guidelines that may require students and faculty to disclose how and when AI was used in their work, and offer guidance on how to properly cite these tools. Data Privacy and Security: Review the potential risks associated with uploading unpublished, proprietary, or personally identifiable information (PII) to public AI services. Establish and enforce clear library policies on what data should never be shared with external tools. Copyright and Intellectual Property (IP): Discuss the murky legal landscape of AI-generated content and IP. Emphasise that AI models are often trained on copyrighted material and that users are responsible for ensuring their outputs do not infringe on existing copyrights. Advocate for using library-licensed, trusted-source AI tools whenever possible. Combating Misinformation: Position the librarian as the essential arbiter against the spread of AI-generated misinformation. Training should include spotting common AI red flags, teaching users how to think sceptically, and promoting the library’s curated, authoritative resources as the gold standard. .wp-block-image img { max-width: 65% !important; margin-left: auto !important; margin-right: auto !important; }

Kamran Kardan, Co-Founder of Zendy, to Speak at QS Eurasia Forum 2025 in Tashkent
We are proud to announce that our Co-Founder, Kamran Kardan, will be a featured speaker at the QS Eurasia Forum 2025, taking place on 25–26 November at Central Asian University in Tashkent, Uzbekistan. This inaugural summit brings together university leaders, policymakers, and education experts from across the Eurasia region to explore collaboration, innovation, and the future of higher education. The forum’s theme, “Broadening Horizons: Building Global Bridges in Higher Education,” focuses on strengthening international partnerships, advancing research excellence, enhancing academic mobility, and shaping future-ready learning ecosystems. Kamran will join a distinguished panel in a session titled: “Building a Globally Recognised University from the Region: Strategies and Success Stories” During the session, Kamran will share insights and strategies on how universities in the region can achieve global recognition, highlighting practical approaches, real-world success stories, and lessons from Zendy’s journey supporting academic research and collaboration. Date & Time: Tuesday, 25 November at 13:30 UZT The QS Eurasia Forum 2025 promises a comprehensive program including keynote speeches, interactive panel discussions, masterclasses, workshops, and extensive networking opportunities. It serves as a pivotal platform for uniting East and West, showcasing best practices, and fostering strategic relationships that will shape the future of higher education in the region. Participation is open via the official QS Eurasia Forum website. We look forward to contributing to this landmark forum, sharing knowledge, and engaging with leaders committed to advancing higher education across Eurasia. .wp-block-image img { max-width: 75% !important; margin-left: auto !important; margin-right: auto !important; }

Kamran Kardan, Co-Founder of Zendy, to Speak at Faculty 360° 2025 Summit
Zendy is pleased to announce that its Co-Founder, Kamran Kardan, will speak at the Faculty 360° 2025 Summit: Beyond the AI Hype – Faculty Futures in a Changing World, an online conference bringing together higher-education leaders, faculty members, and researchers from across the region. Kamran will be sharing how AI tools can empower the strategic direction of research, in his session: The Evolution of Higher Education: AI as the Enterprise Assistant for the Future. Additionalliy he will share how transparent practices, open access, and AI research tools can help university leaders, and faculty navigate the evolving academic landscape. The session is scheduled for 2:45 PM GST. The summit is hosted by Zayed University, in collaboration with New York University Abu Dhabi (NYUAD), Khalifa University, Sorbonne University Abu Dhabi, and the Mohamed Bin Zayed University of Artificial Intelligence (MBZUAI). It focuses on faculty development, AI literacy, research culture, and the evolving role of educators, providing a platform for meaningful discussions on the challenges and opportunities shaping higher education today. Kamran’s participation reflects Zendy’s commitment to supporting libraries, senior leadership, researchers' offices and educators with AI tools and resources that make research more accessible and effective. Event Details: • Date: Friday, 21 November 2025 • Format: Online • Kamran’s Session: 2:45 PM GST For more information about the summit, visit Faculty 360° Summit website .wp-block-image img { max-width: 85% !important; margin-left: auto !important; margin-right: auto !important; }

Digital Information Literacy Guidelines for Academic Libraries
Information literacy is the skill of finding, evaluating, and using information effectively. Data literacy is the skill of understanding numbers and datasets, reading charts, checking how data was collected, and spotting mistakes. Critical thinking is the skill of analysing information, questioning assumptions, and making sound judgments. With so many digital tools today, students and researchers need all three skills, not just to find information, but also to make sense of it and communicate it clearly. Why Academic Libraries Should Offer Literacy Programs Let’s face it: research can be overwhelming. Over 5 million research papers are published every year. This information overload means researchers spend 25-30%1 of their time finding and reviewing academic literature, according to the International Study: Perceptions and Behavior of Researchers. Predatory journals, low-quality datasets, and confusing search results can make learning stressful. Libraries are more than book storage, they’re a place to build practical skills. Programs that teach information and data literacy help students think critically, save time, and feel more confident with research. Key Skills Students, Researchers, and Librarians Need Finding and Using Scholarly Content Knowing how to search a database efficiently is a big deal. Students should learn how to use filters, Boolean logic, subject headings and, of course, intelligent search. They should also know the difference between journal articles, conference papers, and open-access resources. Evaluating Sources and Data Not all information is equal. Programs should teach students how to check if sources are reliable, understand peer review, and spot bias in datasets. A few practical techniques, like cross-checking sources or looking for data provenance, can make research much stronger. Managing Information Ethically Citing sources properly, avoiding plagiarism, and respecting copyright are essentials. Tools like Zotero or Mendeley help keep references organised, so students spend less time managing files and more time on research. Sharing Findings Clearly Communicating is sharing, and sharing is caring. It’s one thing to collect information; it’s another to communicate it. Using infographics, slides, or storytelling techniques to make research more memorable. Ultimately, clear communication ensures that the work they’ve done can be understood, used, and appreciated by others. Frameworks That Guide Literacy Programs ACRL Framework: Provides six key concepts for teaching information literacy. EU DigComp / DigCompEdu: Covers digital skills for students and educators. Data Literacy Project: Helps students understand how to work with datasets, complementing traditional research skills. These frameworks help librarians structure programs so students get consistent, practical guidance. Steps to Build a Digital Literacy Program Audit Campus Needs: Talk to students and faculty, see what resources exist, and find gaps. Set Learning Goals: Decide what students should be able to do at the end, and make goals measurable. Select Content and Tools: Choose databases, software, and datasets that fit the library’s budget and tech setup. Create Short, Modular Lessons: Break skills into manageable pieces that build on each other. Launch and Improve: Introduce the program, gather feedback, and adjust lessons based on what works and what doesn’t. Teaching Strategies and Online Tools Flipped and Embedded Instruction Students watch a short video about search techniques at home, then practice in class. A librarian might join a research methods class, helping students build search strings live. Pre-class quizzes on topics like peer review versus predatory journals prepare students for hands-on exercises. Short Videos and Tutorials Quick videos (2–5 minutes) can teach one skill at a time, like citation management, evaluating sources, or basic data visualisation. Include captions, transcripts, and small practice exercises to reinforce learning. AI Summaries and Chatbots AI tools can summarise articles, suggest keywords, highlight main points, and even draft bibliographies. But they aren’t perfect, they can make mistakes, miss nuances, or misread complex tables. Human oversight is still important. Free Resources and Open Datasets Students can practice with free databases and datasets like DOAJ, arXiv, Kaggle, or Zenodo. Using one of the open-access resources keeps programs affordable while providing real-world examples. Checking if Students Are Learning Before and After Assessments: Simple quizzes or tasks to see how skills improve. Performance Rubrics: Compare beginner, developing, and advanced levels in searching, evaluating, and presenting data. Analytics: Track which videos or tools students use most to improve future lessons. Working With Faculty Embedded Workshops: Librarians teach skills directly tied to assignments. Joint Assignments: Faculty design research projects that naturally teach literacy skills. Faculty Training: Show instructors how to integrate digital literacy into their courses. Tackling Challenges Staff Training: Librarians may need extra help with data tools. Peer mentoring and workshops work well. Limited Budgets: Open access tools, collaborative licensing, and free platforms help make programs feasible. Distance Learners: Make videos and tutorials accessible anytime, account for different time zones and internet access. Looking Ahead AI, open science, and global collaboration are changing research. AI can personalise learning, but it still needs oversight. Open science and FAIR data principles (set of guidelines for making research dataFindable,Accessible,Interoperable, andReusable to both humans and machines) encourage transparency and reproducibility. Libraries can also connect with international partners to share resources and best practices. FAQs How long does a program take to launch?Basic services can start in six months; full programs usually take 1–2 years. Do humanities students need data skills?Yes, focus is more on qualitative analysis and digital humanities tools. Where can libraries find free datasets?Government repositories, Kaggle, Zenodo, and university archives. Can small libraries succeed without data specialists?Yes, faculty collaboration and online resources can cover most needs. .wp-block-image img { max-width: 75% !important; margin-left: auto !important; margin-right: auto !important; }
Address
John Eccles HouseRobert Robinson Avenue,
Oxford Science Park, Oxford
OX4 4GP, United Kingdom